REST API
Haystack can be deployed as a REST API. Using Haystack through an API can benefit developers looking to deploy Question Answering (QA) functionality in their projects, which could be web or mobile apps.
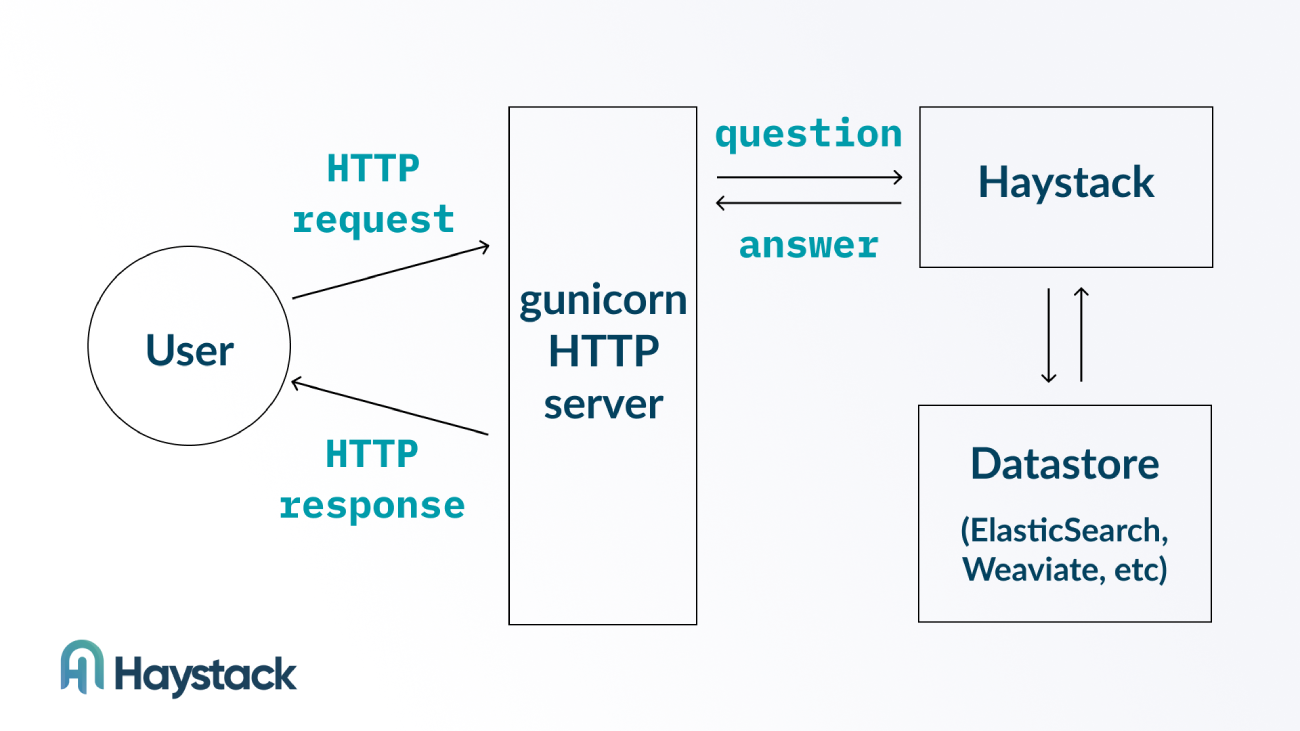
The API uses a web server to receive HTTP requests and pass them on to a running instance of Haystack for processing, before returning Haystack results as an HTTP response.
The diagram below illustrates how the Haystack REST API is structured:
Background: Haystack Pipelines
The Haystack Pipeline is at the core of Haystack’s QA functionality, whether Haystack is used directly through the Python bindings or through a REST API.
A pipeline is defined as a sequence of components where each component performs a dedicated function, e.g., retrieving documents from a document store or extracting an answer to a query from a text document. A pipeline’s components are interconnected through inputs and outputs.
The Haystack REST API exposes an HTTP interface for interacting with a pipeline. For instance, you can use the REST API to send a query submitted in the body of an HTTP request to the Haystack Pipeline. Haystack will then process the request and return the answer to the query in a HTTP response.
When running Haystack as a REST API, you'll need to define the pipeline you'll be using in the API as a YAML file. Check out the Pipelines YAML doc for more details.
The example Haystack pipeline that we’ll be using below is defined in the rest_api/pipeline/pipelines.yaml file.
Setting up a REST API with Haystack
A simple Haystack API is already defined in the project’s default docker-compose.yml file. The easiest way to start this Haystack API is to clone the Haystack repository and then run docker-compose:
git clone https://github.com/deepset-ai/haystack.gitcd haystackdocker-compose pulldocker-compose up
docker-compose will start three Docker containers:
haystack-api: this container runs both Haystack and the HTTP API server.
elasticsearch: the datastore that backs the Haystack QA system in this example.
ui: a simple streamlit user interface that uses the API. The interface is intended only to be used for extractive QA (i.e., answering questions with snippets from the document store). It’s not designed to handle other Haystack use cases like document search or generative QA.
Note: we recommend running Docker with at least 8GB of RAM to ensure that all containers run properly.
By default, the Haystack API container will start with a pipeline defined in the rest_api/pipeline/pipelines.yaml file. If you want to direct the API container to use a YAML file at a different location, you can set the PIPELINE_YAML_PATH environment variable.
Interacting with the Haystack API through a simple user interface
Once you’ve started the Haystack containers, you’ll see the UI by navigating to http://127.0.0.1:8501.
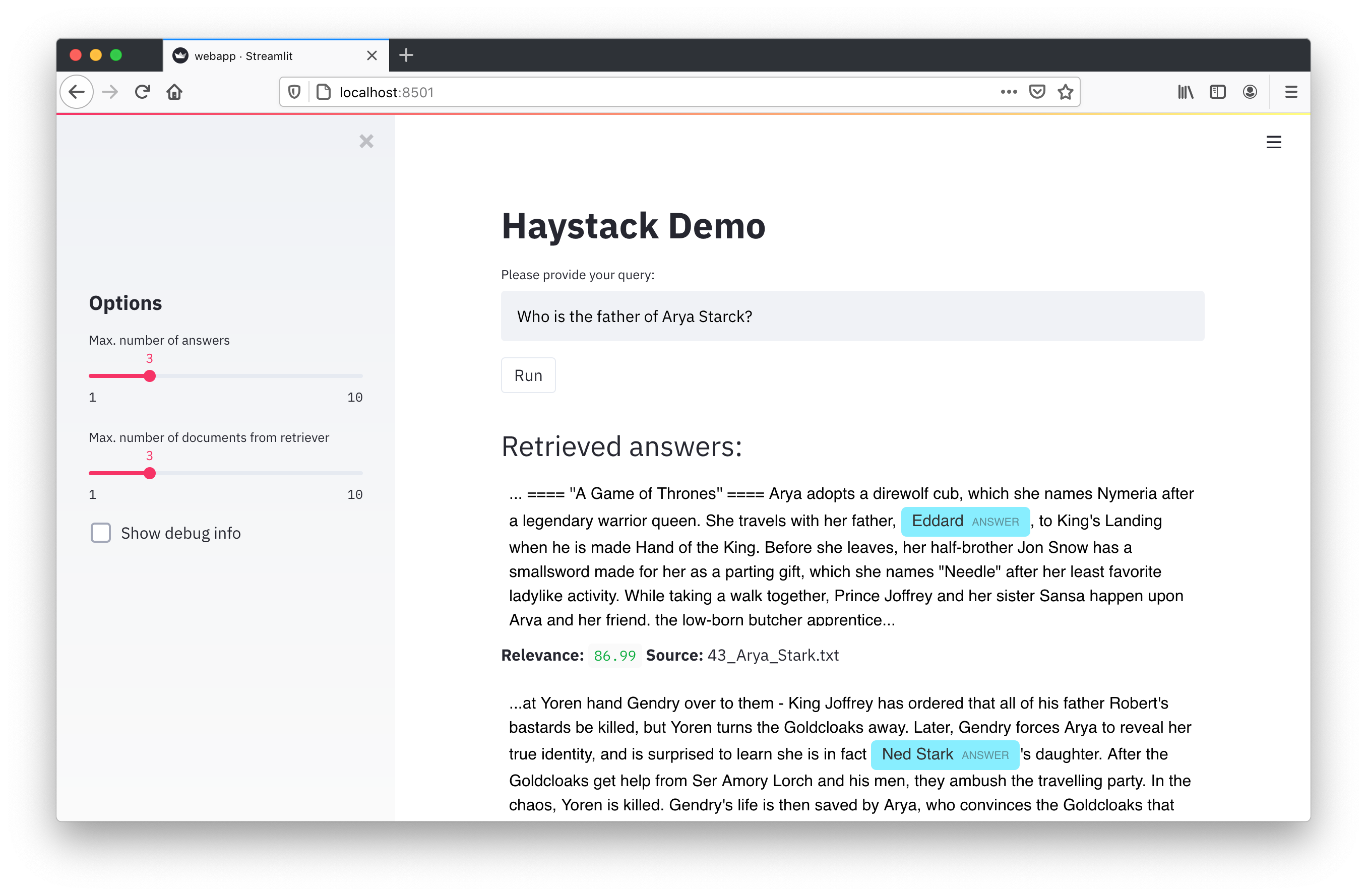
When you enter a query and press Run, the interface will send a REST API request to the haystack-api container that will, in turn, supply the input to the query pipeline that we defined in the YAML file.
Swagger documentation for the Haystack REST API
The API server by default runs on http://127.0.0.1:8000. The API server includes a Swagger documentation site, so to view all endpoints available through the REST API, navigate to the following page: http://127.0.0.1:8000/docs.
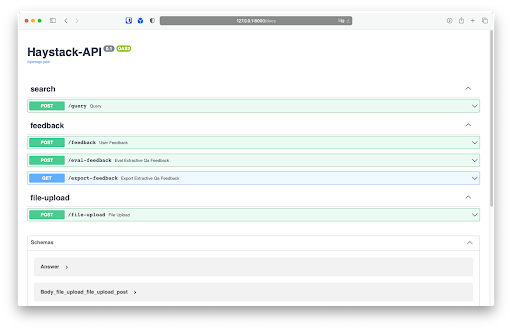
You can use the Swagger page to view the available endpoints and expected input and output formats for each endpoint. The Swagger site also includes the option to send sample API requests and inspect responses.
Hosted Swagger Definitions
See the definitions of the different endpoints available on the latest master version here.
Running HTTP API without Docker
If you prefer to not use Docker with your Haystack API, you can start the REST API server and supporting Haystack pipeline by running the gunicorn server manually with the following command:
gunicorn rest_api.application:app -b 0.0.0.0:8000 -k uvicorn.workers.UvicornWorker -t 300
This is the same command that’s used in the haystack-api container definition.
Indexing documents in the Haystack REST API document store
In the below example, we’ll use an ElasticSearch container pre-loaded with articles about the Game of Thrones series. In a production environment, you’d instead start with either an existing or empty datastore.
There are two options for indexing answers when working with an empty datastore. You can either use an indexing script, or load files through another pipeline exposed through an API.
Option 1: Using an indexing script
You can load documents to your datastore by using a Python script that runs before the Haystack API is initialized. You can find an example script that pre-processes a few files and saves them into the document store in the Build Your First QA System tutorial.
If you go with an indexing script, your REST API startup flow would be:
- Initialize the document store
- Run indexing script
- Start the REST API
- Submit queries
Option 2: Use the REST API to index documents
When using the indexing pipeline, the REST API startup flow would be:
- Initialize the document store
- Start the REST API
- Add documents through the index endpoint
- Submit queries
Our example pipelines.yaml file defines an indexing pipeline—it processes text and PDF files that are submitted to the file-upload API endpoint. So if you submit an API request to the indexing endpoint, the submitted content will get processed by the Indexing pipeline, loaded into Elasticsearch, and made available to the query pipeline.
Here’s how you can add a document through the indexing API by using cURL to make the HTTP request:
curl -X POST -H 'Accept: application/json' -F files='@/Users/alexey/Downloads/Sansa Stark - Wikipedia.pdf' http://127.0.0.1:8000/file-upload
Note: you can use any other HTTP request tool in lieu of cURL. We recommend referring to the Swagger documentation page for complete examples of file-upload requests, as putting them together by hand with cURL can prove difficult.
Querying the Haystack REST API
After adding documents to our document store, we can call the API endpoints directly to retrieve answers. When working with the API’s JSON output, we suggest that you use jq to make the output easier to read. Let’s try querying the Haystack API directly without using the UI. Here’s an example of a query with cURL and jq:
curl -X 'POST' \ 'http://127.0.0.1:8000/query' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "query": "Who is the father of Arya Stark?", "params": {}}'|jq
Note: If you'd like to learn how to pass parameters into your Pipeline, see the Pipeline arguments section.
We get the same information in the response as what we previously saw in the UI:
{ "query":"Who is the father of Arya Stark?", "answers":[ { "answer":"Ned", "type":"extractive", "score":0.9767240881919861, "context":"\n====Season 1====\nArya accompanies her father Ned and her sister Sansa to King's Landing. Before their departure, Arya's half-brother Jon Snow gifts A", "offsets_in_document":[ { "start":46, "end":49 } ], "offsets_in_context":[ { "start":46, "end":49 } ], "document_id":"180c2a6b36369712b361a80842e79356", "meta":{ "name":"43_Arya_Stark.txt" } }, ... ], "documents":[ { "content":"\n===In the Riverlands===\nThe Stark army reaches the Twins, a bridge stronghold controlled by Walder Frey, who agrees to allow the army to cross the river and to commit his troops in return for Robb and Arya Stark marrying two of his children.\nTyrion Lannister suspects his father Tywin, who decides Tyrion and his barbarians will fight in the vanguard, wants him killed...", "content_type":"text", "id":"6b181174d1237878b706e6a12d69e92", "meta":{ "name":"450_Baelor.txt" }, "score":0.8110895501528345 }, ... ]}
Building a custom API endpoint
Existing API endpoints are defined using FastAPI route methods, e.g., in the rest_api/controller/search.py file.
You can add custom endpoints to the Haystack API by defining new API endpoints using the FastAPI methods. Creating new endpoints can be handy for making multiple pipelines available under different API endpoints, or if you need to add custom metrics or modify how parameters are being passed to the pipelines.
Check out the FastAPI intro tutorial for details of how to use FastAPI methods.