Query Classifier Tutorial
![]()
One of the great benefits of using state-of-the-art NLP models like those available in Haystack is that it allows users to state their queries as plain natural language questions: rather than trying to come up with just the right set of keywords to find the answer to their question, users can simply ask their question in much the same way that they would ask it of a (very knowledgeable!) person.
But just because users can ask their questions in "plain English" (or "plain German", etc.), that doesn't mean they always will. For instance, a user might input a few keywords rather than a complete question because they don't understand the pipeline's full capabilities, or because they are so accustomed to keyword search. While a standard Haystack pipeline might handle such queries with reasonable accuracy, for a variety of reasons we still might prefer that our pipeline be sensitive to the type of query it is receiving, so that it behaves differently when a user inputs, say, a collection of keywords instead of a question.
For this reason, Haystack comes with built-in capabilities to distinguish between three types of queries: keyword queries, interrogative queries, and statement queries, described below.
-
Keyword queries can be thought of more or less as lists of words, such as "Alaska cruises summer". While the meanings of individual words may matter in a keyword query, the linguistic connections between words do not. Hence, in a keyword query the order of words is largely irrelevant: "Alaska cruises summer", "summer Alaska cruises", and "summer cruises Alaska" are functionally the same.
-
Interrogative queries (or question queries) are queries phrased as natural language questions, such as "Who was the father of Eddard Stark?". Unlike with keyword queries, word order very much matters here: "Who was the father of Eddard Stark?" and "Who was Eddard Stark the father of?" are very different questions, despite having exactly the same words. (Note that while we often write questions with question marks, Haystack can find interrogative queries without such a dead giveaway!)
-
Statement queries are just declarative sentences, such as "Daenerys loved Jon". These are like interrogative queries in that word order matters—again, "Daenerys loved Jon" and "Jon loved Daenerys" mean very different things—but they are statements instead of questions.
In this tutorial you will learn how to use query classifiers to branch your Haystack pipeline based on the type of query it receives. Haystack comes with two out-of-the-box query classification schemas, each of which routes a given query into one of two branches:
-
Keyword vs. Question/Statement — routes a query into one of two branches depending on whether it is a full question/statement or a collection of keywords.
-
Question vs. Statement — routes a natural language query into one of two branches depending on whether it is a question or a statement.
Furthermore, for each classification schema there are two types of nodes capable of performing this classification: a TransformersQueryClassifier that uses a transformer model, and an SklearnQueryClassifier that uses a more lightweight model built in sklearn.
With all of that explanation out of the way, let's dive in!
Prepare the Environment
Colab: Enable the GPU runtime
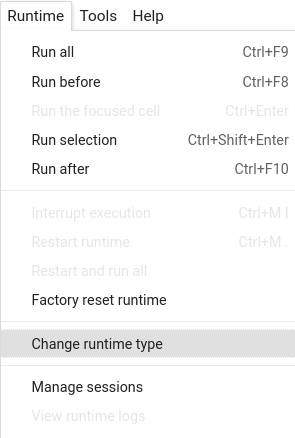
Make sure you enable the GPU runtime to experience decent speed in this tutorial.
Runtime -> Change Runtime type -> Hardware accelerator -> GPU
Next we make sure the latest version of Haystack is installed:
# Install the latest release of Haystack in your own environment
#! pip install farm-haystack
# Install the latest master of Haystack (Colab)
!pip install --upgrade pip
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]
# Install these to allow pipeline visualization
!apt install libgraphviz-dev
!pip install pygraphviz
Trying Some Query Classifiers on their Own
Before integrating query classifiers into our pipelines, let's test them out on their own and see what they actually do. First we initiate a simple, out-of-the-box keyword vs. question/statement SklearnQueryClassifier:
# Here we create the keyword vs question/statement query classifier
from haystack.nodes import SklearnQueryClassifier
keyword_classifier = SklearnQueryClassifier()
Now let's feed some queries into this query classifier. We'll test with one keyword query, one interrogative query, and one statement query. Notice that we don't use any punctuation, such as question marks; this illustrates that the classifier doesn't need punctuation in order to make the right decision.
queries = [
"Arya Stark father", # Keyword Query
"Who was the father of Arya Stark", # Interrogative Query
"Lord Eddard was the father of Arya Stark", # Statement Query
]
We can see below what our classifier does with these queries: "Arya Stark father" is rightly determined to be a keyword query and is sent to branch 2, while both the interrogative query "Who was the father of Arya Stark" and the statement query "Lord Eddard was the father of Arya Stark" are correctly labeled as non-keyword queries, and are thus shipped off to branch 1.
import pandas as pd
k_vs_qs_results = {"Query": [], "Output Branch": [], "Class": []}
for query in queries:
result = keyword_classifier.run(query=query)
k_vs_qs_results["Query"].append(query)
k_vs_qs_results["Output Branch"].append(result[1])
k_vs_qs_results["Class"].append("Question/Statement" if result[1] == "output_1" else "Keyword")
pd.DataFrame.from_dict(k_vs_qs_results)
Next we will illustrate a question vs. statement SklearnQueryClassifier. We define our classifier below; notice that this time we have to explicitly specify the model and vectorizer, since the default for an SklearnQueryClassifier (and a TransformersQueryClassifier) is keyword vs. question/statement classification.
# Here we create the question vs statement query classifier
model_url = (
"https://ext-models-haystack.s3.eu-central-1.amazonaws.com/gradboost_query_classifier_statements/model.pickle"
)
vectorizer_url = (
"https://ext-models-haystack.s3.eu-central-1.amazonaws.com/gradboost_query_classifier_statements/vectorizer.pickle"
)
question_classifier = SklearnQueryClassifier(model_name_or_path=model_url, vectorizer_name_or_path=vectorizer_url)
We will test this classifier on the two question/statement queries from the last go-round:
queries = [
"Who was the father of Arya Stark", # Interrogative Query
"Lord Eddard was the father of Arya Stark", # Statement Query
]
q_vs_s_results = {"Query": [], "Output Branch": [], "Class": []}
for query in queries:
result = question_classifier.run(query=query)
q_vs_s_results["Query"].append(query)
q_vs_s_results["Output Branch"].append(result[1])
q_vs_s_results["Class"].append("Question" if result[1] == "output_1" else "Statement")
pd.DataFrame.from_dict(q_vs_s_results)
And as we see, the question "Who was the father of Arya Stark" is sent to branch 1, while the statement "Lord Eddard was the father of Arya Stark" is sent to branch 2, so we can have our pipeline treat statements and questions differently.
Using Query Classifiers in a Pipeline
Now let's see how we can use query classifiers in a question-answering (QA) pipeline. We start by initiating Elasticsearch:
# In Colab / No Docker environments: Start Elasticsearch from source
! wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
! tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
! chown -R daemon:daemon elasticsearch-7.9.2
import os
from subprocess import Popen, PIPE, STDOUT
es_server = Popen(
["elasticsearch-7.9.2/bin/elasticsearch"], stdout=PIPE, stderr=STDOUT, preexec_fn=lambda: os.setuid(1) # as daemon
)
# wait until ES has started
! sleep 30
Next we fetch some data—for our example we'll use pages from the Game of Thrones wiki—and index it in our DocumentStore:
from haystack.utils import (
print_answers,
print_documents,
fetch_archive_from_http,
convert_files_to_docs,
clean_wiki_text,
launch_es,
)
from haystack.pipelines import Pipeline
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.nodes import BM25Retriever, EmbeddingRetriever, FARMReader, TransformersQueryClassifier
# Download and prepare data - 517 Wikipedia articles for Game of Thrones
doc_dir = "data/tutorial14"
s3_url = "https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt14.zip"
fetch_archive_from_http(url=s3_url, output_dir=doc_dir)
# convert files to dicts containing documents that can be indexed to our datastore
got_docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)
# Initialize DocumentStore and index documents
# launch_es() # Uncomment this line for local Elasticsearch
document_store = ElasticsearchDocumentStore()
document_store.delete_documents()
document_store.write_documents(got_docs)
Pipelines with Keyword vs. Question/Statement Classification
Our first illustration will be a simple retriever-reader QA pipeline, but the choice of which retriever we use will depend on the type of query received: keyword queries will use a sparse BM25Retriever, while question/statement queries will use the more accurate but also more computationally expensive EmbeddingRetriever.
We start by initializing our retrievers and reader:
# Initialize sparse retriever for keyword queries
bm25_retriever = BM25Retriever(document_store=document_store)
# Initialize dense retriever for question/statement queries
embedding_retriever = EmbeddingRetriever(
document_store=document_store, embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1"
)
document_store.update_embeddings(embedding_retriever, update_existing_embeddings=False)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2")
Now we define our pipeline. As promised, the question/statement branch output_1 from the query classifier is fed into an EmbeddingRetriever, while the keyword branch output_2 from the same classifier is fed into a BM25Retriever. Both of these retrievers are then fed into our reader. Our pipeline can thus be thought of as having something of a diamond shape: all queries are sent into the classifier, which splits those queries into two different retrievers, and those retrievers feed their outputs to the same reader.
# Here we build the pipeline
sklearn_keyword_classifier = Pipeline()
sklearn_keyword_classifier.add_node(component=SklearnQueryClassifier(), name="QueryClassifier", inputs=["Query"])
sklearn_keyword_classifier.add_node(
component=embedding_retriever, name="EmbeddingRetriever", inputs=["QueryClassifier.output_1"]
)
sklearn_keyword_classifier.add_node(component=bm25_retriever, name="BM25Retriever", inputs=["QueryClassifier.output_2"])
sklearn_keyword_classifier.add_node(component=reader, name="QAReader", inputs=["BM25Retriever", "EmbeddingRetriever"])
# Visualization of the pipeline
sklearn_keyword_classifier.draw("sklearn_keyword_classifier.png")
Below we can see some results from this choice in branching structure: the keyword query "arya stark father" and the question query "Who is the father of Arya Stark?" generate noticeably different results, a distinction that is likely due to the use of different retrievers for keyword vs. question/statement queries.
# Useful for framing headers
equal_line = "=" * 30
# Run only the dense retriever on the full sentence query
res_1 = sklearn_keyword_classifier.run(query="Who is the father of Arya Stark?")
print(f"\n\n{equal_line}\nQUESTION QUERY RESULTS\n{equal_line}")
print_answers(res_1, details="minimum")
print("\n\n")
# Run only the sparse retriever on a keyword based query
res_2 = sklearn_keyword_classifier.run(query="arya stark father")
print(f"\n\n{equal_line}\nKEYWORD QUERY RESULTS\n{equal_line}")
print_answers(res_2, details="minimum")
The above example uses an SklearnQueryClassifier, but of course we can do precisely the same thing with a TransformersQueryClassifier. This is illustrated below, where we have constructed the same diamond-shaped pipeline.
# Here we build the pipeline
transformer_keyword_classifier = Pipeline()
transformer_keyword_classifier.add_node(
component=TransformersQueryClassifier(), name="QueryClassifier", inputs=["Query"]
)
transformer_keyword_classifier.add_node(
component=embedding_retriever, name="EmbeddingRetriever", inputs=["QueryClassifier.output_1"]
)
transformer_keyword_classifier.add_node(
component=bm25_retriever, name="BM25Retriever", inputs=["QueryClassifier.output_2"]
)
transformer_keyword_classifier.add_node(
component=reader, name="QAReader", inputs=["BM25Retriever", "EmbeddingRetriever"]
)
# Useful for framing headers
equal_line = "=" * 30
# Run only the dense retriever on the full sentence query
res_1 = transformer_keyword_classifier.run(query="Who is the father of Arya Stark?")
print(f"\n\n{equal_line}\nQUESTION QUERY RESULTS\n{equal_line}")
print_answers(res_1, details="minimum")
print("\n\n")
# Run only the sparse retriever on a keyword based query
res_2 = transformer_keyword_classifier.run(query="arya stark father")
print(f"\n\n{equal_line}\nKEYWORD QUERY RESULTS\n{equal_line}")
print_answers(res_2, details="minimum")
Pipeline with Question vs. Statement Classification
Above we saw a potential use for keyword vs. question/statement classification: we might choose to use a less resource-intensive retriever for keyword queries than for question/statement queries. But what about question vs. statement classification?
To illustrate one potential use for question vs. statement classification, we will build a pipeline that looks as follows:
- The pipeline will start with a retriever that every query will go through.
- The pipeline will end with a reader that only question queries will go through.
In other words, our pipeline will be a retriever-only pipeline for statement queries—given the statement "Arya Stark was the daughter of a Lord", all we will get back are the most relevant documents—but it will be a retriever-reader pipeline for question queries.
To make things more concrete, our pipeline will start with a retriever, which is then fed into a TransformersQueryClassifier that is set to do question vs. statement classification. Note that this means we need to explicitly choose the model, since as mentioned previously a default TransformersQueryClassifier performs keyword vs. question/statement classification. The classifier's first branch, which handles question queries, will then be sent to the reader, while the second branch will not be connected to any other nodes. As a result, the last node of the pipeline depends on the type of query: questions go all the way through the reader, while statements only go through the retriever. This pipeline is illustrated below:
# Here we build the pipeline
transformer_question_classifier = Pipeline()
transformer_question_classifier.add_node(component=embedding_retriever, name="EmbeddingRetriever", inputs=["Query"])
transformer_question_classifier.add_node(
component=TransformersQueryClassifier(model_name_or_path="shahrukhx01/question-vs-statement-classifier"),
name="QueryClassifier",
inputs=["EmbeddingRetriever"],
)
transformer_question_classifier.add_node(component=reader, name="QAReader", inputs=["QueryClassifier.output_1"])
# Visualization of the pipeline
transformer_question_classifier.draw("transformer_question_classifier.png")
And below we see the results of this pipeline: with a question query like "Who is the father of Arya Stark?" we get back answers returned by a reader, but with a statement query like "Arya Stark was the daughter of a Lord" we just get back documents returned by a retriever.
# Useful for framing headers
equal_line = "=" * 30
# Run the retriever + reader on the question query
res_1 = transformer_question_classifier.run(query="Who is the father of Arya Stark?")
print(f"\n\n{equal_line}\nQUESTION QUERY RESULTS\n{equal_line}")
print_answers(res_1, details="minimum")
print("\n\n")
# Run only the retriever on the statement query
res_2 = transformer_question_classifier.run(query="Arya Stark was the daughter of a Lord.")
print(f"\n\n{equal_line}\nSTATEMENT QUERY RESULTS\n{equal_line}")
print_documents(res_2)
About us
This Haystack notebook was made with love by deepset in Berlin, Germany
We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
Get in touch: Twitter | LinkedIn | Slack | GitHub Discussions | Website
By the way: we're hiring!